Measuring the size of a regular language is NP-Hard
In this post we will examine an interesting connection between the -complete CNF-SAT problem and the problem of computing the amount of words generated by some efficient representation of a formal language. Here, I call a way of representing a formal language efficient, if it has a polynomially-long encoding but can possibly describe an exponentially-large formal language. Examples of such efficient representations are nondeteministic finite automations and regular expressions.
Formal definition of the problem
We can formally define the problem of determining the language size the following way:
Name: NFA Language Size
Input: A nondeterministic finite automata (NFA) and a number .
Question: Is ?
Proof of NP-hardness
We will construct a reduction from the -complete CNF-SAT problem. Consider a formula with clauses and variables:
- Create an NFA with the alphabet .
- For every variable and clause create a state . Intuitively, if the NFA is in the state , it means that it has already read symbols of some variable assignment where clause is zero.
- For each clause of the formula, construct a boolean cube with containing variables that are negated in the clause and containing positive variables (other variables are mapped to ). By doing this, we essentially construct a cube that is the negation of the clause. In other words, all full variable assignments such that will make the clause (and the whole formula ) false. For all create the following transitions:
- Set if .
- Set if .
- Set and if .
- Mark all states with as initial: .
- Mark all states with as final: .
By construction, will accept any variable assignment where . As has exactly variable assignments, it is satisfiable if and only if the set of accepted variable assignments has at most elements.
This reduction can clearly be done in polynomial time.
Intuition & Example
Consider the following function:
The cubes that describe variable assignments where is false are **10, 1*01 and 11*0 (variable order: ). These three cubes make the first, second and the third clauses false, respectively.
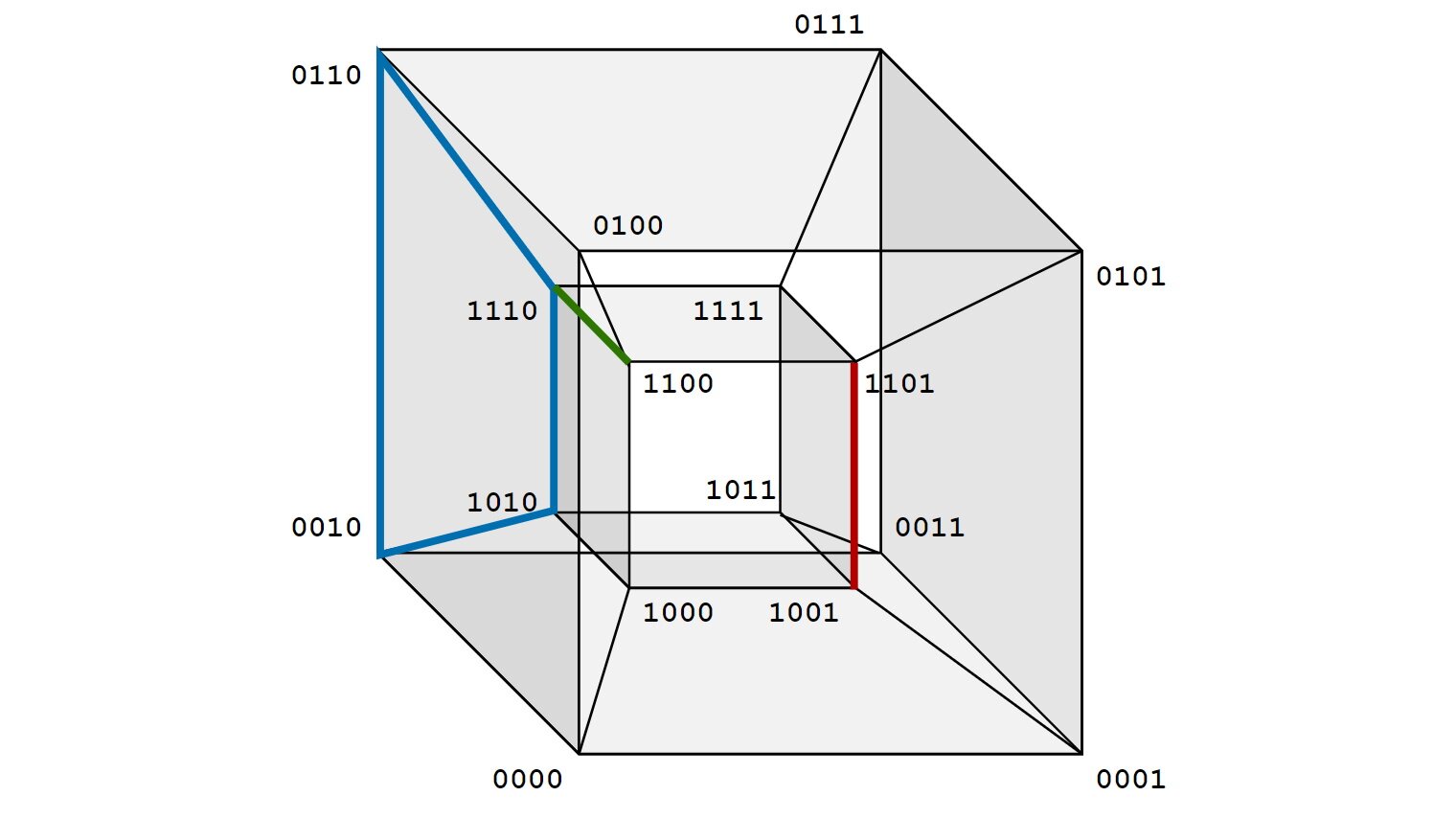
We can visualize all possible variable assignments with a 4-dimensional cube (as has 4 variables):

In this cube, every edge connects assignments that differ in exactly one bit (i.e. hamming distance = 1). Any lower dimensional cubes that are subgraphs of this cube are implicants if the vertices in the subgraph cover only assignments where the function is true. If a lower dimensional cube isn’t a part of some higher dimensional cube that still covers only assignments where the function is true, such a cube is a prime implicant. In this case, if we think of CNF-clauses as implicants of the negated function, then we can visualize them the following way:

The idea of the reduction is that if we can count the amount of vertices covered by these cubes, then we can compare this amount to the total number of vertices and if it is less than where is the number of variables, then the function is satisfiable, otherwise not. The problem is that implicants aren’t always disjoint. So, the satisfiability problem is essentially the problem of comparing with the size of the union of variable assignments described by cubes.
These variable assignments that are parts of some cube(s) can be accepted with a nondeterministic finite automata (NFA) with states. We can create such an NFA for each clause and then union them by marking multiple states as initial. In this example, we get the following NFA:

The top row of the NFA accepts variable assignments generated by the 11*0 cube, the middle row corresponds to the 1*01 cube and the bottom one - to **10. is satisfiable if and only if there is at least one word of length 4, such that this NFA doesn’t accept it.
Converting the NFA to a BDD
The idea of this reduction can be used to compute all the satisfying assignments of . Consider the example above - we can apply the Rabin-Scott algorithm to convert the NFA to a DFA:

The computed DFA will always be acyclic (without the -node), because the initial NFA had no cycles in it. The satisfying assignments are the ones that are not accepted by the NFA. Therefore, they are exactly the paths of length , leading to . A program can easily output all satisfying assignments with a DFS or BFS-search in this tree.
If we replace with the positive leaf and all final states with a negative leaf (the transitions after them can be removed), then the graph will become an ordered binary decision diagram (OBDD) of :

Of course, the nodes should be renamed to variable names:

The Rabin-Scott algorithm doesn’t always output minimal deterministic automations and therefore in most cases the OBDD will also not be minimal, like in this case where the redundant checks are clearly seen. In order to get a ROBDD we will still need to apply the elimination and the isomorphism rules (remove redundant checks and reuse subtrees):

NP-Complete special case
We can tweak the problem defined above to make it belong to :
Name: NFA Rejected m-string
Input: A nondeterministic finite automata (NFA) and a unary-encoded number .
Question: Exists such a string of length such that ?
This problem is in , because a string of length can be used as a certificate. Then, by using the idea of the Rabin-Scott theorem, we can compute all potential states after transitions and therefore test whether the given string is rejected or not in time in , which is polynomial in the length of the input. The -hardness can be shown with a reduction from CNF-SAT as follows:
- Consider a formula with clauses and variables.
- Construct an NFA by following the same steps as in the proof of -hardness of
NFA Language Size. - Set .
is satisfiable if and only if there is a rejected string of length in which is exactly some satisfying assignment for . Clearly, this is a polynomial-time reduction.
Finding any rejected string is NP-Complete
We can also define another version of the problem and proof it’s -completeness:
Name: NFA Rejected String
Input: A nondeterministic finite automata (NFA) and a unary-encoded number .
Question: Exists such a string with such that ?
This problem is in , because a string of length can be used as a certificate, like in the NFA Rejected m-string problem.
We will prove -hardness by reducing NFA Rejected m-string to this problem. Consider an NFA and a number :
- Create new nodes .
- For all and , set .
- Mark as initial: .
- Mark as final: .
- Set .
By construction, the new NFA will accept all strings of length or less. Thus, there is a rejected string of length if and only if there is a rejected string of length at most in the new NFA. Obviously, this is a polynomial-time reduction.
A few words about complexity
These problems illustrate an interesting connection between -complete problems, that can be solved in polynomial time by nondeterministic turing machines and the problem of just counting the language size described by an NFA. By the Rabin-Scott theorem, it is possible to convert any NFA to an equivalent DFA, but the worst-case complexity of the algorithm is , because a set with elements has subsets and all of these subsets will be reachable in the worst-case. Would the complexity of the subset-construction be polynomial, then it would mean that as we can just search for all paths in the DFA that lead to after exactly transitions (these paths are exactly the variable assignments that satisfy ).
The reduction discussed above can also be done in reverse. Any set of cubes can be transformed to a boolean function in conjunctive normal form. So, if and the CNF-SAT problem is solvable in polynomial time, then it is also possible to compare with the size of the union of some arbitrary boolean cubes. The cube union size problem is essentially a special case of the inclusion–exclusion principle, where the formula to compute the size of a union of sets is also exponentially long, because the amount of possible intersections grows exponentially.
It seems impossible to compute the size of the union of some arbitrary cubes in polynomial time, because the variable assignments that some cube describes is exponential in the length of the encoding of the cube. And the amount of ways to intersect some cubes is also exponential. Any polynomial encoding for a cube would allow us to distinguish between an exponential amount of cubes. However, the amount of ways to intersect some -variable-cubes is in , so it is impossible to precisely encode the union of these cubes with a polynomially long encoding. However, it could be possible to divide the search space so that it is still possible to compare with the size of the union of the cubes in polynomial time. Of course, these thoughts aren’t even close to a formal proof that .