Using the PA=LU factorization to solve linear systems of equations for many right-hand sides efficiently
Linear systems of equations come up in almost any technical discipline. The PA=LU factorization method is a well-known numerical method for solving those types of systems of equations against multiple input vectors. It is also possible to preserve numerical stability by implementing some pivot strategy. In this post we will consider performance and numerical stability issues and try to cope with them by using the PA = LU factorization.
Idea behind the algorithm
Suppose we have a matrix and some set of vectors and we need to solve for all . Of course, we can just run the Gaussian elimination algorithm for each vector and compute the upper-triangular form of the matrix and then backward-substitute the vector . However, if the set of vectors is large or the matrix itself is big, this is inefficient because we have to convert the matrix to upper-triangular form times.
While doing Gaussian elimination, all row operations are applied both to the matrix and the vector. But when we choose what operation should be applied in some step, we never consider the entries of the vector. The key idea behind the factorization algorithm is to compute the upper-triangular form of the matrix once and save all steps that have been performed so that we can perform the same steps on the current vector without recomputing the upper-triangular form of for backward substitution. All Gaussian elimination steps can be encoded in a matrix , such that if we multiply it by some vector , will apply all the operations performed while computing the upper-triangular form of to . After that we can just do backward substitution to find .
During Gaussian elimination it is possible that we are forced to swap some rows, for example if the pivot on the diagonal is zero. As we will see, it is also a good idea to swap rows not only when we are forced to do so. Anyway, in order for the algorithm to work with any matrix , we need to store the permutations of the rows of in some way. For simplicity, we will store the permutation in a permutation matrix that essentially just swaps rows.
So, formally speaking, we are interested in finding such matrices , and , such that where is the permutation matrix, is a lower-triangular matrix and is an upper triangular matrix. We need and to be triangular matrices in order to be able to quickly solve linear systems of equations with them.
Forward and backward substitution
As already mentioned above, we need to implement forward and backward substitution in order to proceed with the factorization algorithm:
# Solves a linear system of equations Lx = b where the L matrix is lower-triangular
def forward_substitution(L, b):
m = len(b)
x = np.empty(m)
for v in range(m):
if L[v][v] == 0:
# the value on the diagonal is zero
x[v] = 0
# the current variable's value is irrelevant
continue
# calculate v-th variable value
value = b[v]
# subtract linear combination of the already known variables
# in the bottom left corner of the matrix
for i in range(v):
value -= L[v][i] * x[i]
# divide by the coefficient by the v-th variable to get it's value
value /= L[v][v]
# store the value in the resulting vector
x[v] = value
return x
Analogously, we can implement backward substitution:
# Solves a linear system of equations Ux = b where the U matrix is upper-triangular
def backward_substitution(U, b):
m = len(b)
x = np.empty(m)
for v in range(m - 1, -1, -1):
if U[v][v] == 0:
# the value on the diagonal is zero
x[v] = 0
continue
# calculate v-th variable value
value = b[v]
# subtract linear combination of the already known variables
# in the top right corner of the matrix
for i in range(v + 1, m, 1):
value -= U[v][i] * x[i]
# divide by the coefficient before the i-th variable to get it's value
value /= U[v][v]
# store the value in the resulting vector
x[v] = value
return x
Solutions for non-homogeneous systems of equations are affine subspaces. If the input matrix is full-rank, i.e. doesn’t reduce the dimension of the vector space during a linear transformation, then there will be only one solution vector and the algorithms will calculate it correctly. For the sake of simplicity these algorithms just set the corresponding variables to zero if there is a zero on the diagonal, so in case the matrix is not full-rank, the algorithms will return only one vector from a set of vectors. In order to get the whole solution affine subspace it is necessary to give back a parametrized set of vectors.
PA=LU factorization
The factorization algorithm consists of the following steps:
- Initialize with the initial matrix and let and be the identity matrices. We will transform to upper-triangular form.
- Find some non-zero pivot element in the current column of the matrix.
- If the found pivot element is not on the diagonal, swap the corresponding rows in the and matrices. Also, apply the swap to the part of the matrix under the main diagonal.
- Subtract the row with the pivot on the diagonal from all rows underneath so that all element under the pivot element become zero. After has been eliminated by subtracting from row , set the coefficient such that, in other words, .
- Continue from step 2 with the next column.
The idea behind the adjustment of the matrix in step 3 is to add to the row to be eliminated and thus reverse this step. We only need to calculate the elements under the diagonal of the matrix because the row to be eliminated is always under the pivot row.
Example
Consider the following matrix:
We can start computing the factorization by writing the initial decomposition as follows:
For the first column, let’s choose the pivot in the second row. It is not on the diagonal, so we must swap the first two rows:
Now the pivot is on the diagonal and it is time to subtract of the first row from the second row and of the first row from the third row. We write these coefficients to the first column of the matrix, accordingly:
Now we proceed with the second column. Assume we choose as a pivot. is not on the diagonal, so we must swap the second row with the third one. This time we also need to swap the corresponding rows in the matrix:
We are now ready to eliminate from the third row by subtracting of the second row from it:
This is the decomposition of .
Non-stable implementation
We can implement the decomposition algorithm described above in Python the following way:
# Compute the PA = LU decomposition of the matrix A
def plu(A):
m = len(A)
P = np.identity(m) # create an identity matrix of size m
L = np.identity(m)
for x in range(m):
pivotRow = x
if A[pivotRow][x] == 0:
# search for a non-zero pivot
for y in range(x + 1, m, 1):
if A[y][x] != 0:
pivotRow = y
break
if A[pivotRow][x] == 0:
# we didn't find any row with a non-zero leading coefficient
# that means that the matrix has all zeroes in this column
# so we don't need to search for pivots after all for the current column x
continue
# did we just use a pivot that is not on the diagonal?
if pivotRow != x:
# so we need to swap the part of the pivot row after x including x
# with the same right part of the x row where the pivot was expected
for i in range(x, m, 1):
# swap the two values columnwise
(A[x][i], A[pivotRow][i]) = (A[pivotRow][i], A[x][i])
# we must save the fact that we did this swap in the permutation matrix
# swap the pivot row with row x
P[[x, pivotRow]] = P[[pivotRow, x]]
# we also need to swap the rows in the L matrix
# however, the relevant part of the L matrix is only the bottom-left corner
# and before x
for i in range(x):
(L[x][i], L[pivotRow][i]) = (L[pivotRow][i], L[x][i])
# now the pivot row is x
# search for rows where the leading coefficient must be eliminated
for y in range(x + 1, m, 1):
currentValue = A[y][x]
if currentValue == 0:
# variable already eliminated, nothing to do
continue
pivot = A[x][x]
assert pivot != 0 # just in case, we already made sure the pivot is not zero
pivotFactor = currentValue / pivot
# subtract the pivot row from the current row
A[y][x] = 0
for i in range(x + 1, m, 1):
A[y][i] -= pivotFactor * A[x][i]
# write the pivot factor to the L matrix
L[y][x] = pivotFactor
# the pivot must anyway be at the correct position if we found at least one
# non-zero leading coefficient in the current column x
assert A[x][x] != 0
for y in range(x + 1, m, 1):
assert A[y][x] == 0
return (P, L, A)
We are now interested in solving with the computed decomposition of into . It follows that :
We can reorder components of the vector by multiplying it with (let ) and then solve for using forward substitution (as is lower-triangular). Intuitively, is the vector with all the Gaussian elimination steps applied to it. After that, we can compute by solving using backward substitution (as is upper-triangular).
We can implement these steps as follows:
def plu_solve(A, b):
(P, L, U) = plu(A)
b = np.matmul(P, b) # multiply matrix P with vector b
y = forward_substitution(L, b)
x = backward_substitution(U, y)
return x
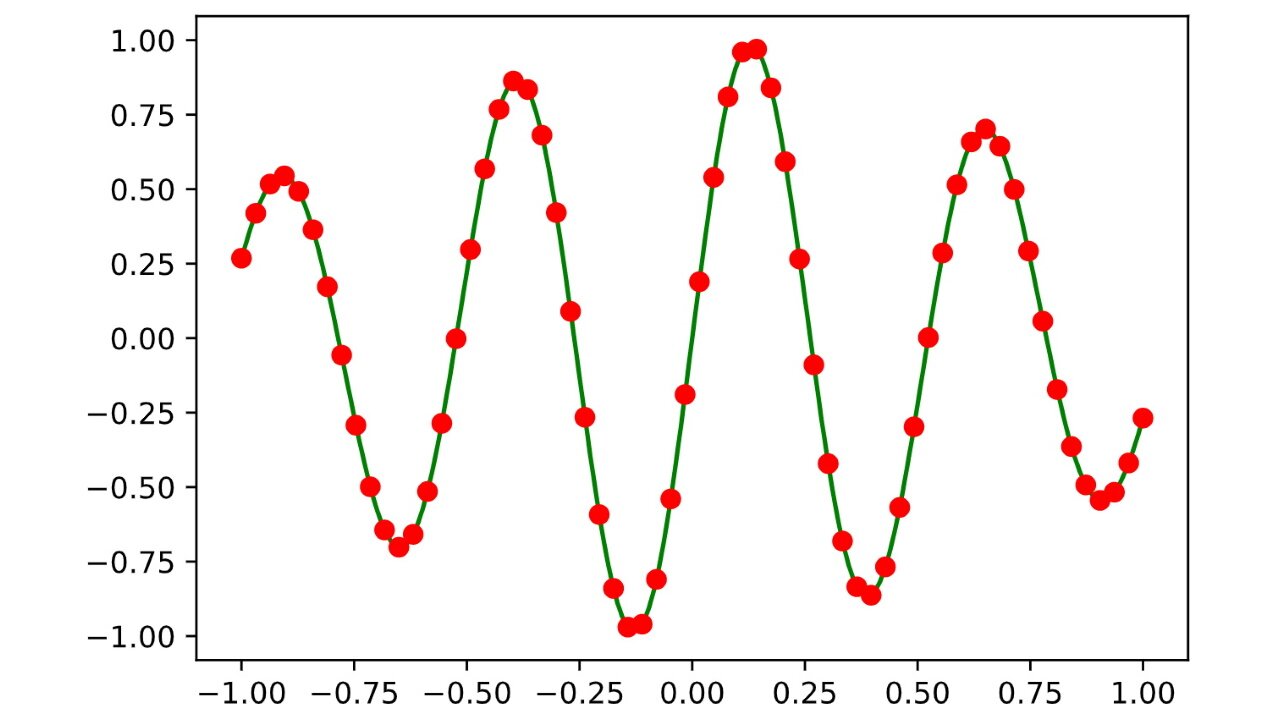
However, there it still a problem with the above implementation of plu. We can illustrate it by approximating the function on the interval with the decomposition applied to a Vandermonde matrix:

As you can see, the approximation isn’t entirely right. The low-degree terms of the polynomial approximating are getting lost due to rounding errors in floating point arithmetic. These low-degree terms are exactly the ones that are responsible for approximating the right part of the graph and that’s why we see rounding errors there.
Numerical stability
The issue that causes such precision problems lies in choosing the wrong pivot element. For example, consider the following matrix
where is some very small number.
If we choose as a pivot, then we need to subtract the second row multiplied with to perform an elimination step. As is very small, is very big. So by choosing such a pivot, we not only preserve in the matrix but also add a very large number to it, like in this case.
There are many advanced strategies to cope with this problem, but one of the most easy and effective ways to improve numerical stability is to just choose the element with the greatest absolute value as the pivot.
Thus, we can improve the implementation by adjusting the code responsible for choosing the pivot:
def palu(A):
m = len(A)
P = np.identity(m) # create an identity matrix of size m
L = np.identity(m)
for x in range(m):
pivotRow = x
# search for the best pivot
for y in range(x + 1, m, 1):
if abs(A[y][x]) > abs(A[pivotRow][x]):
pivotRow = y
if A[pivotRow][x] == 0:
# we didn't find any row with a non-zero leading coefficient
# that means that the matrix has all zeroes in this column
# so we don't need to search for pivots after all for the current column x
continue
# did we just use a pivot that is not on the diagonal?
if pivotRow != x:
# so we need to swap the part of the pivot row after x including x
# with the same right part of the x row where the pivot was expected
for i in range(x, m, 1):
# swap the two values columnwise
(A[x][i], A[pivotRow][i]) = (A[pivotRow][i], A[x][i])
# we must save the fact that we did this swap in the permutation matrix
# swap the pivot row with row x
P[[x, pivotRow]] = P[[pivotRow, x]]
# we also need to swap the rows in the L matrix
# however, the relevant part of the L matrix is only the bottom-left corner
# and before x
for i in range(x):
(L[x][i], L[pivotRow][i]) = (L[pivotRow][i], L[x][i])
# now the pivot row is x
# search for rows where the leading coefficient must be eliminated
for y in range(x + 1, m, 1):
currentValue = A[y][x]
if currentValue == 0:
# variable already eliminated, nothing to do
continue
pivot = A[x][x]
assert pivot != 0 # just in case, we already made sure the pivot is not zero
pivotFactor = currentValue / pivot
# subtract the pivot row from the current row
A[y][x] = 0
for i in range(x + 1, m, 1):
A[y][i] -= pivotFactor * A[x][i]
# write the pivot factor to the L matrix
L[y][x] = pivotFactor
# the pivot must anyway be at the correct position if we found at least one
# non-zero leading coefficient in the current column x
assert A[x][x] != 0
for y in range(x + 1, m, 1):
assert A[y][x] == 0
return (P, L, A)
With this implementation we get a much better approximation of :

Using only one matrix to store the decomposition
As is a lower-triangular matrix and is upper-triangular, we can actually create only one matrix (apart from ) to store the decomposition. It also allows us to simplify the way we do swap operations:
def forward_substitution(L, b):
m = len(b)
x = np.empty(m)
for v in range(m):
# calculate v-th variable value
value = b[v]
# subtract linear combination of the already known variables
# in the bottom left corner of the matrix
for i in range(v):
value -= L[v][i] * x[i]
# no need to divide by L[v][v] as it is implicitly 1, by construction
# (this 1 is not stored in the matrix)
# store the value in the resulting vector
x[v] = value
return x
def plu(A):
m = len(A)
P = np.identity(m)
for x in range(m):
pivotRow = x
# search for the best pivot
for y in range(x + 1, m, 1):
if abs(A[y][x]) > abs(A[pivotRow][x]):
pivotRow = y
if A[pivotRow][x] == 0:
# we didn't find any row with a non-zero leading coefficient
# that means that the matrix has all zeroes in this column
# so we don't need to search for pivots after all for the current column x
continue
# did we just use a pivot that is not on the diagonal?
if pivotRow != x:
# swap the pivot row with the current row in both A and L matrices
A[[x, pivotRow]] = A[[pivotRow, x]]
# we must save the fact that we did this swap in the permutation matrix
# swap the pivot row with row x
P[[x, pivotRow]] = P[[pivotRow, x]]
# now the pivot row is x
# search for rows where the leading coefficient must be eliminated
for y in range(x + 1, m, 1):
currentValue = A[y][x]
if currentValue == 0:
# variable already eliminated, nothing to do
continue
pivot = A[x][x]
assert pivot != 0 # just in case, we already made sure the pivot is not zero
pivotFactor = currentValue / pivot
# subtract the pivot row from the current row
for i in range(x + 1, m, 1):
A[y][i] -= pivotFactor * A[x][i]
# write the pivot factor to the L matrix
A[y][x] = pivotFactor
return (P, A)
def plu_solve(P, LU, b):
b = np.matmul(P, b)
y = forward_substitution(LU, b)
x = backward_substitution(LU, y)
return x
It is possible to further optimize the algorithms by removing the permutation matrix and replacing it with a simple array that permutes it’s indices (or some other permutation datastructure).
As already mentioned in the beginning of the post, the key advantage of the decomposition is that it allows us to solve linear systems of equations for many input vectors from by doing Gaussian elimination only once
(P, LU) = plu(A)
for b in B:
solution = plu_solve(P, LU, b)
instead of doing full Gaussian elimination times.
Let be the size of the vector and be an matrix. Then the complexity of computing the factorization is . If we optimize the permutation matrix so that permuting elements takes time in , then the solving algorithm’s complexity is .
Therefore, the overall complexity of the algorithm that takes and a set of vectors and solves for every (as shown in the code snippet above) is , which is better than if we apply Gaussian elimination times.