How propositional logic minimization and gray codes are connected
In this post I will introduce an interesting connection between gray codes and the problem of minimizing propositional logic formulas in disjunctive normal forms (DNF’s). Both of these concepts are related to the Hamming distance between two binary sequences, which is the amount of bits that need to be flipped in one sequence in order to obtain the other one.
Boolean functions and n-dimensional cubes
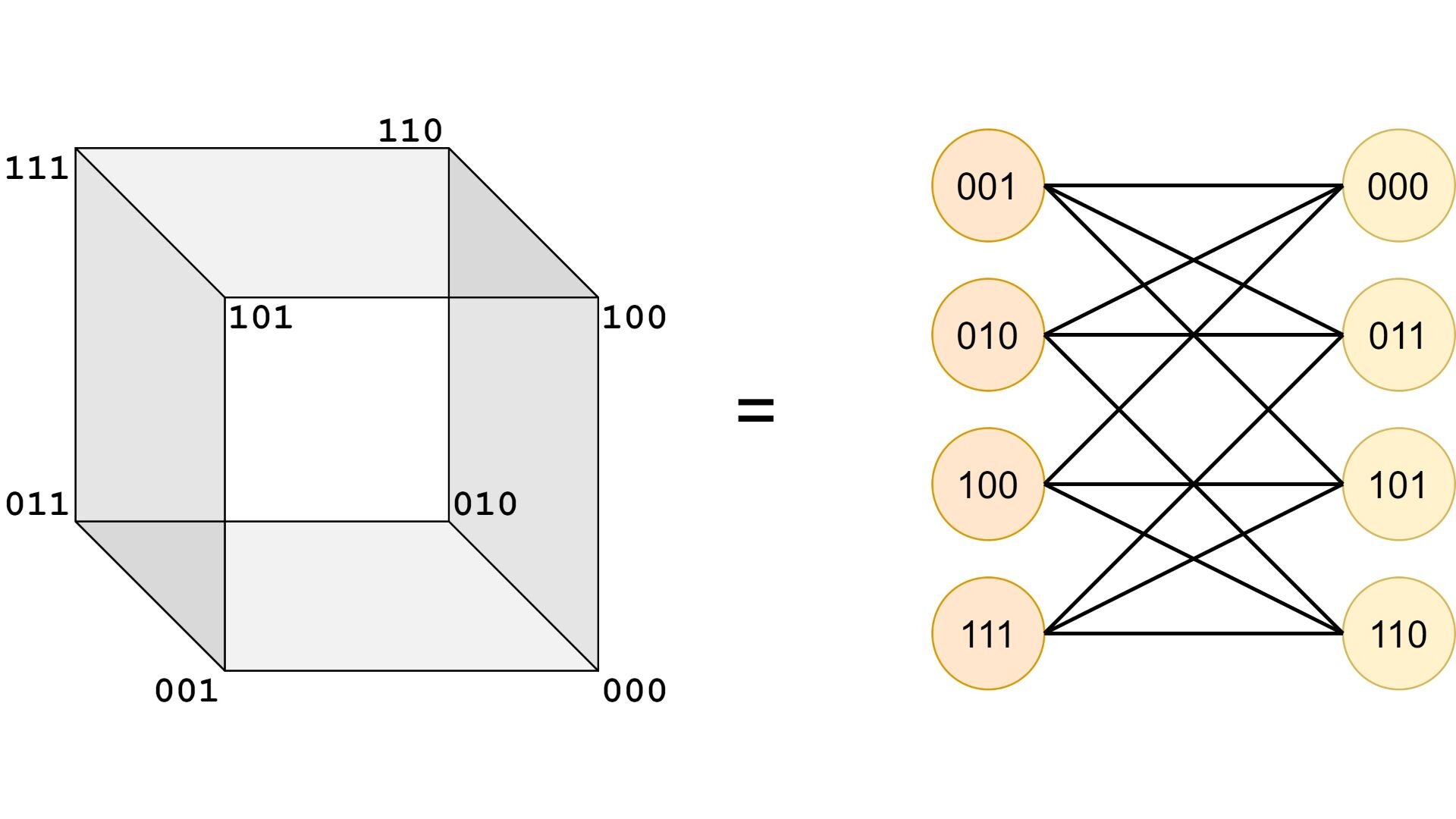
Any boolean function with variables can be visualized as some subset of vertices in an -dimensional cube. For example, for , the cube looks like this:

In such cubes every edge connects vertices that correspond to variable assignments differing in exactly one variable. In other words, any disjoint -dimensional sub-cubes of an -dimensional cube, viewed as boolean cubes (a. k. a. partial variable assignments), are adjacent.
Variable assignments that have the same number of ones can be grouped together:

It is easy to see that assignments from the blue segment have hamming distance 2 when compared with the assignments from the red segment. Analogously, this is also true for the green and brown segments. It also holds, that assignments in one segment have hamming distance 2 because of the way we grouped them. This leads us to the idea that boolean cubes are bipartite graphs if we draw edges between variable assignments that have hamming distance 1:

With the above described intuition we can now formulate and prove the following statements:
Theorem 1
Let be the gray code for and be the gray code for . Assuming , it holds that:
- and are both even .
- and are both odd .
Proof: by induction on for all (I’ve defined in this post and proved that this definition is equivalent to another definition of gray codes).
Induction base: (): There is no way of choosing different and such that at least one assumption above is true, so the statements hold trivially.
Induction base: ():
Induction step: ():
- If both and are in the first half of , then the statements hold directly by induction hypothesis.
- If both and are in the second half of (formally: ), then, by definition of , we have:
- So, in this case, due to it follows that and the statements hold by induction hypothesis.
- Otherwise, without losing generality, we can assume that is in the first half of and — in the second half of .
- Formally, this means and .
- By the definition of , it holds that .
- By the symmetry theorem I proved in this post:
If , then both statements are true, because the first bit of needs to be flipped (see formula above) and the leading 1-bit of should be prepended, meaning that the hamming distance cannot be less than 2.
Otherwise, because subtracting doesn’t affect whether is even or odd, we can use the induction hypothesis for and which states that:
- Unfortunately, the first bit of gets flipped, so for , from the induction hypothesis we can only conclude that:
However, by definition of we know that a leading bit gets prepended, which increases the overall hamming distance as .
We therefore conclude that:
Corollary 1
-dimensional boolean cubes are bipartite graphs — we can partition variable assignments based on whether they are gray codes of even numbers or whether they are gray codes of odd numbers. Theorem 1 guarantees that no edges in the -dimensional cube connect vertices inside one group.
Hamming distance for boolean cubes
In order to prove the lemma below, we need to define hamming distance for boolean cubes. Intuitively, 2 cubes have hamming distance 1 iff there exist two assignments (vertices) in the -dimensional cube, such that the hamming distance between them is one, or, in other words, the shortest path between the corresponding vertices is 1.
More generally speaking, two cubes have hamming distance if the shortest path between some assignment of the first cube cube to some assignment from the second one is . For example, the hamming distance between the following boolean cubes inside an -dimensional cube is 2, because the shortest path (one of them is marked red) has length 2 ().

Formally, let and be boolean cubes. We define:
We will first need the following statements for the proof of the main theorem (theorem 2) below:
Lemma 1
A minterm is covered by some other implicant , iff there exists some other minterm , , such that .
Proof: (): covers means for all . As , there exists at least one variable such that . We can thus define as follows:
- If , define .
- If and , define .
- Finally, define .
By construction, it holds that and .
(): If there exists a with , then, by definition of , there exists exactly one variable such that and for all other variables , it holds that . We define accordingly:
- If , set .
- Set .
By construction, covers .
Corollary 2
A minterm is a prime implicant iff for all other minterms , the hamming distance .
Proof: By definition, a cube is a prime implicant iff it is not covered by any other implicant. Accordingly, a minterm (each minterm is also a cube) is a prime implicant iff it is not covered by any other implicant. Not being covered by any other implicant means, by the lemma 1 above, that for all other minterms , the hamming distance .
Corollary 3
There exist at most models that are prime implicants.
Proof: Corollary 2, taken in conjunction with the fact that every vertex in the -dimensional cube has adjacent vertices, implies that it is impossible to choose models (out of variable assignments) such that no models among them have hamming distance 1. Accordingly, there cannot exist (different) models that are prime implicants.
Corollary 4
There are at most (distinct) essential prime implicants.
Proof:
- Suppose we managed to pick essential prime implicants — let the set contain them — .
- Every is essential. Intuitively, this means that it must contribute at least one model that other essential prime implicants in cannot contribute.
- Formally, it holds that for every there exists a model , such that there is no other , , that contains this model ( denotes the set of models covers):
- It follows that models must have hamming distance 1 among each other.
- This means, by corollary 2, that all these models by themselves must be prime implicants.
- We get a contradiction, because corollary 3 states that it is impossible to choose models that are prime implicants.
Theorem 2
For any , there exist exactly 2 boolean functions and with variables, such that the smallest possible DNF’s describing these functions consist of terms and each term has exactly literals. All other boolean functions with variables have smaller minimal DNF’s.
Moreover, and have the following properties:
Proof: Each boolean function is a set of models. Clearly, this set is a subset of the set of vertices of an -dimensional cube, built as described at the beginning of this post.
By the theorem 1 above, stating that gray codes for even numbers have hamming distance at least 2 among each other, combined with corollary 2, it follows that all models of are prime implicants. Analogously, all models of are prime implicants. Corollary 3 states, that there exist at most models that are prime implicants, so we conclude that and reach this maximum.
We now argue why it also follows that there are no other ways of choosing models that are prime implicants, apart from the ways models for and — and are chosen:
- Assume we found models which are prime implicants. Let be the set of these models.
- Also, assume and .
- This means that and , or, in other words, there exist variable models , , such that and .
- As , because a vertex in an -dimensional cube has adjacent vertices, there exists with and .
- If it is not he case, that (for example, if ), then we directly get a contradiction.
- Analogously, there exists with and .
- Therefore, it holds that , where is the set of all models. Note that and are disjoint. In other words, contains models from the remaining vertices of the cube.
- Suppose we we know all vertices apart from and that are in (these nodes are “chosen” out of remaining vertices).
- We now estimate the maximum number of edges that are not inside , i.e. that either connect nodes outside with each other or connect nodes inside with nodes outside of :
- There are edges total. So, at least the following amount of edges must connect nodes inside :
- We therefore get a contradiction.
The above reasoning can be visualized for as follows (we consider the worst-case set in this visualization):

It follows from the above that and are exactly the boolean functions which have the most models that are prime implicants — all other boolean functions have less.
Now, we will need the Quine’s Theorem, which reads as follows:
Each minimal disjunction of cubes is a disjunction of prime implicants.
In the present context, because of corollary 4 stating that there are at most essential prime implicants, this means that every minimal DNF has at most terms (each term satisfies the whole formula iff the variable assignment is described by the corresponding prime implicant).
All (essential) prime implicants of and are models, so each term in the minimal DNF is guaranteed to have literals, making it the maximal DNF possible:
- If some other boolean function has less than essential prime implicants, it will have less than terms in the minimal DNF.
- If some other boolean function has essential prime implicants, then there will be at least one cube of order at least 1, making the corresponding term of the minimal DNF have less than literals.
The properties of the and functions mentioned in the statement of this theorem hold by construction of the models — gray codes of even numbers have an even number of ones and gray codes of odd numbers have an odd number of ones. This is not hard to prove — but it is also not necessary at this point because of the above argument about the uniqueness of the sets of models. This was also the idea I mentioned at the beginning of the post. It also follows that , because both and have disjoint models out of possible variable assignments.
This completes the proof.
Example
Consider all boolean functions with variables. There are such functions. These are the minimal DNF’s of all these 256 functions (I computed them with the Quine-McCluskey algorithm), the first 8 columns of the table represent the right-hand side of the truth table. The order of the assignments in the truth table is the order in which we count in binary. Please note there may be different minimal DNF’s that correspond to a particular boolean function, if that is the case then the corresponding table entry contains one of them.
| R1 | R2 | R3 | R4 | R5 | R6 | R7 | R8 | Minimal DNF |
|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | a ∧ b ∧ c |
| 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | a ∧ b ∧ ¬c |
| 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | a ∧ b |
| 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | a ∧ ¬b ∧ c |
| 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | a ∧ c |
| 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | a ∧ ¬b ∧ c ∨ a ∧ b ∧ ¬c |
| 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | a ∧ c ∨ a ∧ b |
| 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | a ∧ ¬b ∧ ¬c |
| 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | a ∧ ¬b ∧ ¬c ∨ a ∧ b ∧ c |
| 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | a ∧ ¬c |
| 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | a ∧ ¬c ∨ a ∧ b |
| 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | a ∧ ¬b |
| 0 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | a ∧ ¬b ∨ a ∧ c |
| 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | a ∧ ¬b ∨ a ∧ ¬c |
| 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | a |
| 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | ¬a ∧ b ∧ c |
| 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | b ∧ c |
| 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | ¬a ∧ b ∧ c ∨ a ∧ b ∧ ¬c |
| 0 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | b ∧ c ∨ a ∧ b |
| 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | ¬a ∧ b ∧ c ∨ a ∧ ¬b ∧ c |
| 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | b ∧ c ∨ a ∧ c |
| 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | ¬a ∧ b ∧ c ∨ a ∧ ¬b ∧ c ∨ a ∧ b ∧ ¬c |
| 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | b ∧ c ∨ a ∧ c ∨ a ∧ b |
| 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | a ∧ ¬b ∧ ¬c ∨ ¬a ∧ b ∧ c |
| 0 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | a ∧ ¬b ∧ ¬c ∨ b ∧ c |
| 0 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | ¬a ∧ b ∧ c ∨ a ∧ ¬c |
| 0 | 0 | 0 | 1 | 1 | 0 | 1 | 1 | a ∧ ¬c ∨ b ∧ c |
| 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | ¬a ∧ b ∧ c ∨ a ∧ ¬b |
| 0 | 0 | 0 | 1 | 1 | 1 | 0 | 1 | a ∧ ¬b ∨ b ∧ c |
| 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | ¬a ∧ b ∧ c ∨ a ∧ ¬b ∨ a ∧ ¬c |
| 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | b ∧ c ∨ a |
| 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | ¬a ∧ b ∧ ¬c |
| 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | ¬a ∧ b ∧ ¬c ∨ a ∧ b ∧ c |
| 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | b ∧ ¬c |
| 0 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | b ∧ ¬c ∨ a ∧ b |
| 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | ¬a ∧ b ∧ ¬c ∨ a ∧ ¬b ∧ c |
| 0 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | ¬a ∧ b ∧ ¬c ∨ a ∧ c |
| 0 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | a ∧ ¬b ∧ c ∨ b ∧ ¬c |
| 0 | 0 | 1 | 0 | 0 | 1 | 1 | 1 | b ∧ ¬c ∨ a ∧ c |
| 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | ¬a ∧ b ∧ ¬c ∨ a ∧ ¬b ∧ ¬c |
| 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | ¬a ∧ b ∧ ¬c ∨ a ∧ ¬b ∧ ¬c ∨ a ∧ b ∧ c |
| 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | b ∧ ¬c ∨ a ∧ ¬c |
| 0 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | b ∧ ¬c ∨ a ∧ ¬c ∨ a ∧ b |
| 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | ¬a ∧ b ∧ ¬c ∨ a ∧ ¬b |
| 0 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | ¬a ∧ b ∧ ¬c ∨ a ∧ ¬b ∨ a ∧ c |
| 0 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | b ∧ ¬c ∨ a ∧ ¬b |
| 0 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | b ∧ ¬c ∨ a |
| 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | ¬a ∧ b |
| 0 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | ¬a ∧ b ∨ b ∧ c |
| 0 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | ¬a ∧ b ∨ b ∧ ¬c |
| 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | b |
| 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | a ∧ ¬b ∧ c ∨ ¬a ∧ b |
| 0 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | ¬a ∧ b ∨ a ∧ c |
| 0 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | a ∧ ¬b ∧ c ∨ ¬a ∧ b ∨ b ∧ ¬c |
| 0 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | a ∧ c ∨ b |
| 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | a ∧ ¬b ∧ ¬c ∨ ¬a ∧ b |
| 0 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | a ∧ ¬b ∧ ¬c ∨ ¬a ∧ b ∨ b ∧ c |
| 0 | 0 | 1 | 1 | 1 | 0 | 1 | 0 | ¬a ∧ b ∨ a ∧ ¬c |
| 0 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | a ∧ ¬c ∨ b |
| 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | ¬a ∧ b ∨ a ∧ ¬b |
| 0 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | ¬a ∧ b ∨ a ∧ ¬b ∨ a ∧ c |
| 0 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | ¬a ∧ b ∨ a ∧ ¬b ∨ a ∧ ¬c |
| 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | b ∨ a |
| 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | ¬a ∧ ¬b ∧ c |
| 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | ¬a ∧ ¬b ∧ c ∨ a ∧ b ∧ c |
| 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | ¬a ∧ ¬b ∧ c ∨ a ∧ b ∧ ¬c |
| 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | ¬a ∧ ¬b ∧ c ∨ a ∧ b |
| 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | ¬b ∧ c |
| 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | ¬b ∧ c ∨ a ∧ c |
| 0 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | a ∧ b ∧ ¬c ∨ ¬b ∧ c |
| 0 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | ¬b ∧ c ∨ a ∧ b |
| 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | ¬a ∧ ¬b ∧ c ∨ a ∧ ¬b ∧ ¬c |
| 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | ¬a ∧ ¬b ∧ c ∨ a ∧ ¬b ∧ ¬c ∨ a ∧ b ∧ c |
| 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | ¬a ∧ ¬b ∧ c ∨ a ∧ ¬c |
| 0 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | ¬a ∧ ¬b ∧ c ∨ a ∧ ¬c ∨ a ∧ b |
| 0 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | ¬b ∧ c ∨ a ∧ ¬b |
| 0 | 1 | 0 | 0 | 1 | 1 | 0 | 1 | ¬b ∧ c ∨ a ∧ ¬b ∨ a ∧ c |
| 0 | 1 | 0 | 0 | 1 | 1 | 1 | 0 | ¬b ∧ c ∨ a ∧ ¬c |
| 0 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | ¬b ∧ c ∨ a |
| 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | ¬a ∧ c |
| 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | ¬a ∧ c ∨ b ∧ c |
| 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | a ∧ b ∧ ¬c ∨ ¬a ∧ c |
| 0 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | ¬a ∧ c ∨ a ∧ b |
| 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | ¬a ∧ c ∨ ¬b ∧ c |
| 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | c |
| 0 | 1 | 0 | 1 | 0 | 1 | 1 | 0 | a ∧ b ∧ ¬c ∨ ¬a ∧ c ∨ ¬b ∧ c |
| 0 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | a ∧ b ∨ c |
| 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | a ∧ ¬b ∧ ¬c ∨ ¬a ∧ c |
| 0 | 1 | 0 | 1 | 1 | 0 | 0 | 1 | a ∧ ¬b ∧ ¬c ∨ ¬a ∧ c ∨ b ∧ c |
| 0 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | ¬a ∧ c ∨ a ∧ ¬c |
| 0 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | ¬a ∧ c ∨ a ∧ ¬c ∨ a ∧ b |
| 0 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | ¬a ∧ c ∨ a ∧ ¬b |
| 0 | 1 | 0 | 1 | 1 | 1 | 0 | 1 | a ∧ ¬b ∨ c |
| 0 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | ¬a ∧ c ∨ a ∧ ¬b ∨ a ∧ ¬c |
| 0 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | c ∨ a |
| 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | ¬a ∧ ¬b ∧ c ∨ ¬a ∧ b ∧ ¬c |
| 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | ¬a ∧ ¬b ∧ c ∨ ¬a ∧ b ∧ ¬c ∨ a ∧ b ∧ c |
| 0 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | ¬a ∧ ¬b ∧ c ∨ b ∧ ¬c |
| 0 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | ¬a ∧ ¬b ∧ c ∨ b ∧ ¬c ∨ a ∧ b |
| 0 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | ¬a ∧ b ∧ ¬c ∨ ¬b ∧ c |
| 0 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | ¬a ∧ b ∧ ¬c ∨ ¬b ∧ c ∨ a ∧ c |
| 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | ¬b ∧ c ∨ b ∧ ¬c |
| 0 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | ¬b ∧ c ∨ b ∧ ¬c ∨ a ∧ b |
| 0 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | ¬a ∧ ¬b ∧ c ∨ ¬a ∧ b ∧ ¬c ∨ a ∧ ¬b ∧ ¬c |
| 0 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | ¬a ∧ ¬b ∧ c ∨ ¬a ∧ b ∧ ¬c ∨ a ∧ ¬b ∧ ¬c ∨ a ∧ b ∧ c |
| 0 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | ¬a ∧ ¬b ∧ c ∨ b ∧ ¬c ∨ a ∧ ¬c |
| 0 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | ¬a ∧ ¬b ∧ c ∨ b ∧ ¬c ∨ a ∧ ¬c ∨ a ∧ b |
| 0 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | ¬a ∧ b ∧ ¬c ∨ ¬b ∧ c ∨ a ∧ ¬b |
| 0 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | ¬a ∧ b ∧ ¬c ∨ ¬b ∧ c ∨ a ∧ ¬b ∨ a ∧ c |
| 0 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | ¬b ∧ c ∨ b ∧ ¬c ∨ a ∧ ¬c |
| 0 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | ¬b ∧ c ∨ b ∧ ¬c ∨ a |
| 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | ¬a ∧ c ∨ ¬a ∧ b |
| 0 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | ¬a ∧ c ∨ ¬a ∧ b ∨ b ∧ c |
| 0 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | ¬a ∧ c ∨ b ∧ ¬c |
| 0 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | ¬a ∧ c ∨ b |
| 0 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | ¬b ∧ c ∨ ¬a ∧ b |
| 0 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | ¬a ∧ b ∨ c |
| 0 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | ¬b ∧ c ∨ ¬a ∧ b ∨ b ∧ ¬c |
| 0 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | c ∨ b |
| 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | a ∧ ¬b ∧ ¬c ∨ ¬a ∧ c ∨ ¬a ∧ b |
| 0 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | a ∧ ¬b ∧ ¬c ∨ ¬a ∧ c ∨ ¬a ∧ b ∨ b ∧ c |
| 0 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | ¬a ∧ c ∨ b ∧ ¬c ∨ a ∧ ¬c |
| 0 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | ¬a ∧ c ∨ a ∧ ¬c ∨ b |
| 0 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | ¬b ∧ c ∨ ¬a ∧ b ∨ a ∧ ¬b |
| 0 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | ¬a ∧ b ∨ a ∧ ¬b ∨ c |
| 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | ¬a ∧ c ∨ b ∧ ¬c ∨ a ∧ ¬b |
| 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | c ∨ b ∨ a |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ¬a ∧ ¬b ∧ ¬c |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | ¬a ∧ ¬b ∧ ¬c ∨ a ∧ b ∧ c |
| 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | ¬a ∧ ¬b ∧ ¬c ∨ a ∧ b ∧ ¬c |
| 1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | ¬a ∧ ¬b ∧ ¬c ∨ a ∧ b |
| 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | ¬a ∧ ¬b ∧ ¬c ∨ a ∧ ¬b ∧ c |
| 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | ¬a ∧ ¬b ∧ ¬c ∨ a ∧ c |
| 1 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | ¬a ∧ ¬b ∧ ¬c ∨ a ∧ ¬b ∧ c ∨ a ∧ b ∧ ¬c |
| 1 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | ¬a ∧ ¬b ∧ ¬c ∨ a ∧ c ∨ a ∧ b |
| 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | ¬b ∧ ¬c |
| 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | a ∧ b ∧ c ∨ ¬b ∧ ¬c |
| 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | ¬b ∧ ¬c ∨ a ∧ ¬c |
| 1 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | ¬b ∧ ¬c ∨ a ∧ b |
| 1 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | ¬b ∧ ¬c ∨ a ∧ ¬b |
| 1 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | ¬b ∧ ¬c ∨ a ∧ c |
| 1 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | ¬b ∧ ¬c ∨ a ∧ ¬b ∨ a ∧ ¬c |
| 1 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | ¬b ∧ ¬c ∨ a |
| 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | ¬a ∧ ¬b ∧ ¬c ∨ ¬a ∧ b ∧ c |
| 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | ¬a ∧ ¬b ∧ ¬c ∨ b ∧ c |
| 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | ¬a ∧ ¬b ∧ ¬c ∨ ¬a ∧ b ∧ c ∨ a ∧ b ∧ ¬c |
| 1 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | ¬a ∧ ¬b ∧ ¬c ∨ b ∧ c ∨ a ∧ b |
| 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | ¬a ∧ ¬b ∧ ¬c ∨ ¬a ∧ b ∧ c ∨ a ∧ ¬b ∧ c |
| 1 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | ¬a ∧ ¬b ∧ ¬c ∨ b ∧ c ∨ a ∧ c |
| 1 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | ¬a ∧ ¬b ∧ ¬c ∨ ¬a ∧ b ∧ c ∨ a ∧ ¬b ∧ c ∨ a ∧ b ∧ ¬c |
| 1 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | ¬a ∧ ¬b ∧ ¬c ∨ b ∧ c ∨ a ∧ c ∨ a ∧ b |
| 1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | ¬a ∧ b ∧ c ∨ ¬b ∧ ¬c |
| 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | ¬b ∧ ¬c ∨ b ∧ c |
| 1 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | ¬a ∧ b ∧ c ∨ ¬b ∧ ¬c ∨ a ∧ ¬c |
| 1 | 0 | 0 | 1 | 1 | 0 | 1 | 1 | ¬b ∧ ¬c ∨ b ∧ c ∨ a ∧ b |
| 1 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | ¬a ∧ b ∧ c ∨ ¬b ∧ ¬c ∨ a ∧ ¬b |
| 1 | 0 | 0 | 1 | 1 | 1 | 0 | 1 | ¬b ∧ ¬c ∨ b ∧ c ∨ a ∧ c |
| 1 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | ¬a ∧ b ∧ c ∨ ¬b ∧ ¬c ∨ a ∧ ¬b ∨ a ∧ ¬c |
| 1 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | ¬b ∧ ¬c ∨ b ∧ c ∨ a |
| 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | ¬a ∧ ¬c |
| 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | a ∧ b ∧ c ∨ ¬a ∧ ¬c |
| 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | ¬a ∧ ¬c ∨ b ∧ ¬c |
| 1 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | ¬a ∧ ¬c ∨ a ∧ b |
| 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | a ∧ ¬b ∧ c ∨ ¬a ∧ ¬c |
| 1 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | ¬a ∧ ¬c ∨ a ∧ c |
| 1 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | a ∧ ¬b ∧ c ∨ ¬a ∧ ¬c ∨ b ∧ ¬c |
| 1 | 0 | 1 | 0 | 0 | 1 | 1 | 1 | ¬a ∧ ¬c ∨ a ∧ c ∨ a ∧ b |
| 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | ¬a ∧ ¬c ∨ ¬b ∧ ¬c |
| 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | a ∧ b ∧ c ∨ ¬a ∧ ¬c ∨ ¬b ∧ ¬c |
| 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | ¬c |
| 1 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | a ∧ b ∨ ¬c |
| 1 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | ¬a ∧ ¬c ∨ a ∧ ¬b |
| 1 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | ¬a ∧ ¬c ∨ a ∧ ¬b ∨ a ∧ c |
| 1 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | a ∧ ¬b ∨ ¬c |
| 1 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | ¬c ∨ a |
| 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | ¬a ∧ ¬c ∨ ¬a ∧ b |
| 1 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | ¬a ∧ ¬c ∨ b ∧ c |
| 1 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | ¬a ∧ ¬c ∨ ¬a ∧ b ∨ b ∧ ¬c |
| 1 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | ¬a ∧ ¬c ∨ b |
| 1 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | a ∧ ¬b ∧ c ∨ ¬a ∧ ¬c ∨ ¬a ∧ b |
| 1 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | ¬a ∧ ¬c ∨ b ∧ c ∨ a ∧ c |
| 1 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | a ∧ ¬b ∧ c ∨ ¬a ∧ ¬c ∨ ¬a ∧ b ∨ b ∧ ¬c |
| 1 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | ¬a ∧ ¬c ∨ a ∧ c ∨ b |
| 1 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | ¬b ∧ ¬c ∨ ¬a ∧ b |
| 1 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | ¬b ∧ ¬c ∨ ¬a ∧ b ∨ b ∧ c |
| 1 | 0 | 1 | 1 | 1 | 0 | 1 | 0 | ¬a ∧ b ∨ ¬c |
| 1 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | ¬c ∨ b |
| 1 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | ¬b ∧ ¬c ∨ ¬a ∧ b ∨ a ∧ ¬b |
| 1 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | ¬a ∧ ¬c ∨ a ∧ ¬b ∨ b ∧ c |
| 1 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | ¬a ∧ b ∨ a ∧ ¬b ∨ ¬c |
| 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | ¬c ∨ b ∨ a |
| 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | ¬a ∧ ¬b |
| 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | a ∧ b ∧ c ∨ ¬a ∧ ¬b |
| 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | a ∧ b ∧ ¬c ∨ ¬a ∧ ¬b |
| 1 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | ¬a ∧ ¬b ∨ a ∧ b |
| 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | ¬a ∧ ¬b ∨ ¬b ∧ c |
| 1 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | ¬a ∧ ¬b ∨ a ∧ c |
| 1 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | a ∧ b ∧ ¬c ∨ ¬a ∧ ¬b ∨ ¬b ∧ c |
| 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | ¬a ∧ ¬b ∨ a ∧ c ∨ a ∧ b |
| 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | ¬a ∧ ¬b ∨ ¬b ∧ ¬c |
| 1 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | a ∧ b ∧ c ∨ ¬a ∧ ¬b ∨ ¬b ∧ ¬c |
| 1 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | ¬a ∧ ¬b ∨ a ∧ ¬c |
| 1 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | ¬a ∧ ¬b ∨ a ∧ ¬c ∨ a ∧ b |
| 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | ¬b |
| 1 | 1 | 0 | 0 | 1 | 1 | 0 | 1 | a ∧ c ∨ ¬b |
| 1 | 1 | 0 | 0 | 1 | 1 | 1 | 0 | a ∧ ¬c ∨ ¬b |
| 1 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | ¬b ∨ a |
| 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | ¬a ∧ ¬b ∨ ¬a ∧ c |
| 1 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | ¬a ∧ ¬b ∨ b ∧ c |
| 1 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | a ∧ b ∧ ¬c ∨ ¬a ∧ ¬b ∨ ¬a ∧ c |
| 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | ¬a ∧ ¬b ∨ b ∧ c ∨ a ∧ b |
| 1 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | ¬a ∧ ¬b ∨ ¬a ∧ c ∨ ¬b ∧ c |
| 1 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | ¬a ∧ ¬b ∨ c |
| 1 | 1 | 0 | 1 | 0 | 1 | 1 | 0 | a ∧ b ∧ ¬c ∨ ¬a ∧ ¬b ∨ ¬a ∧ c ∨ ¬b ∧ c |
| 1 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | ¬a ∧ ¬b ∨ a ∧ b ∨ c |
| 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | ¬b ∧ ¬c ∨ ¬a ∧ c |
| 1 | 1 | 0 | 1 | 1 | 0 | 0 | 1 | ¬b ∧ ¬c ∨ ¬a ∧ c ∨ b ∧ c |
| 1 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | ¬b ∧ ¬c ∨ ¬a ∧ c ∨ a ∧ ¬c |
| 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | ¬a ∧ ¬b ∨ a ∧ ¬c ∨ b ∧ c |
| 1 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | ¬a ∧ c ∨ ¬b |
| 1 | 1 | 0 | 1 | 1 | 1 | 0 | 1 | ¬b ∨ c |
| 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | ¬a ∧ c ∨ a ∧ ¬c ∨ ¬b |
| 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | ¬b ∨ c ∨ a |
| 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | ¬a ∧ ¬b ∨ ¬a ∧ ¬c |
| 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | a ∧ b ∧ c ∨ ¬a ∧ ¬b ∨ ¬a ∧ ¬c |
| 1 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | ¬a ∧ ¬b ∨ b ∧ ¬c |
| 1 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | ¬a ∧ ¬b ∨ b ∧ ¬c ∨ a ∧ b |
| 1 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | ¬a ∧ ¬c ∨ ¬b ∧ c |
| 1 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | ¬a ∧ ¬c ∨ ¬b ∧ c ∨ a ∧ c |
| 1 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | ¬a ∧ ¬c ∨ ¬b ∧ c ∨ b ∧ ¬c |
| 1 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | ¬a ∧ ¬b ∨ b ∧ ¬c ∨ a ∧ c |
| 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | ¬a ∧ ¬b ∨ ¬a ∧ ¬c ∨ ¬b ∧ ¬c |
| 1 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | a ∧ b ∧ c ∨ ¬a ∧ ¬b ∨ ¬a ∧ ¬c ∨ ¬b ∧ ¬c |
| 1 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | ¬a ∧ ¬b ∨ ¬c |
| 1 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | ¬a ∧ ¬b ∨ a ∧ b ∨ ¬c |
| 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | ¬a ∧ ¬c ∨ ¬b |
| 1 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | ¬a ∧ ¬c ∨ a ∧ c ∨ ¬b |
| 1 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | ¬b ∨ ¬c |
| 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | ¬b ∨ ¬c ∨ a |
| 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | ¬a |
| 1 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | b ∧ c ∨ ¬a |
| 1 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | b ∧ ¬c ∨ ¬a |
| 1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | ¬a ∨ b |
| 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | ¬b ∧ c ∨ ¬a |
| 1 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | ¬a ∨ c |
| 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | ¬b ∧ c ∨ b ∧ ¬c ∨ ¬a |
| 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | ¬a ∨ c ∨ b |
| 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | ¬b ∧ ¬c ∨ ¬a |
| 1 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | ¬b ∧ ¬c ∨ b ∧ c ∨ ¬a |
| 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | ¬a ∨ ¬c |
| 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | ¬a ∨ ¬c ∨ b |
| 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | ¬a ∨ ¬b |
| 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | ¬a ∨ ¬b ∨ c |
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | ¬a ∨ ¬b ∨ ¬c |
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
We see that the there exist exactly two longest minimal DNF’s that correspond to the functions that we described in theorem 2 above: